using Random
using StatsBase
Random.seed!(777) # 乱数シードを設定
T = 1000
# Q学習のシミュレーション
function q_learning(alpha::Float64, beta::Float64) :: Array{Array{Int, 1}, 1}
# あらかじめ型や配列の長さを指定しておく
Prob = Float64[0.3, 0.7]
c = Array{Int}(undef, T)
r = Array{Int}(undef, T)
# 0で初期化
Q = zeros(2)
for t = 1:T
# 選択確率を計算
p_A = 1 / (1 + exp( - beta * (Q[1] - Q[2])))
# [0,1]の一様乱数を使って行動を選択
if rand() < p_A
c[t] = 1
r[t] = Int(rand() < Prob[1])
else
c[t] = 2
r[t] = Int(rand() < Prob[2])
end
# 行動価値の更新
Q[c[t]] = Q[c[t]] + alpha * (r[t] - Q[c[t]])
# 50試行ごとにパラメータ値をフリップ
if t % 50 == 0
Prob[1], Prob[2] = Prob[2], Prob[1]
end
end
return [c, r]
end;
# 対数尤度を計算
function log_likelihood(params::Array{Float64}, c::Array{Int}, r::Array{Int}) :: Float64
alpha, beta = params
Q = zeros(2)
log_lik = 0.0
for t = 1:T
p_A = 1 / (1 + exp( - beta * (Q[1] - Q[2])))
log_lik += log(c[t] == 1 ? p_A : 1 - p_A)
Q[c[t]] = Q[c[t]] + alpha * (r[t] - Q[c[t]])
end
return log_lik
end;3月に関学の清水先生が主催しているベイズ塾合宿というイベントに参加することになりました.プログラムを確認したところメインはJuliaのハンズオンということらしいので,予習のためにJuliaを使ってなんかやろうというのがこの記事の趣旨です.
シミュレーション
今回はJuliaによる簡単なシミュレーションの実践として,2腕バンディット問題と強化学習モデル(Q-learning)を扱います.別に題材は何でもよかったのですが,シンプルに強化学習モデルおよび関連する研究が好きなので選んでみました.内容そのものは基本的に 片平 (2018) に準拠しています(名著です).
アルゴリズム
2腕バンディット問題では,取りうる2つの行動から得られる報酬の期待値を経験を通じて学習する状況を考えます.具体的には,各時点
ここでの
意思決定のモデルとしてはsoftmax選択を考えます.softmax選択は経験に基づく価値が高い選択肢を高確率で選びつつも,低確率で価値の低い選択肢を探索するような選択のルールであり,探索と活用のトレードオフ(exploration-exploitation tradeoff)のもとでの適切な選択モデルの一つです.ここでは2肢強制選択の状況なので,行動
と表せます.ここでの
Juliaによる実装
以下に2腕バンディット問題のシミュレーションを行うコードを示します.q_learning()関数で特定のパラメータのもとでのエージェントの行動選択と報酬を確率的に生成します.log_likelihood()関数は,パラメータ値と生成されたデータから計算した対数尤度を返します.
Juliaは動的型付け言語なので明示的に型を指定しなくても動作しますが,指定することで計算効率が向上することがあります.以下のコードでは関数の引数や戻り値に対して型を指定しています.
今回は試行数を
それでは実際にシミュレーションを行い,得られたデータをもとに最尤推定を行ってみましょう.
using Optim
alpha = 0.3 # 学習率
beta = 2.0 # 逆温度
# シミュレーション
c, r = q_learning(alpha, beta)
# 最尤推定
f = params -> -log_likelihood(params, c, r) # 無名関数は->で定義可能(JSライクですね)
result = optimize(
f, # 目的関数
[0.0, 0.0], # パラメータの下限
[1.0, 3.0], # パラメータの上限
[rand(), rand()], # 初期値
Fminbox(LBFGS()) # 最適化アルゴリズム
)
# 結果の表示
println("Minimum: ", Optim.minimum(result))
println("Minimizer: ", Optim.minimizer(result))
println("AIC: ", 2 * Optim.minimum(result) + 2 * length(Optim.minimizer(result)))Minimum: 621.8124773861042
Minimizer: [0.22076509555284965, 2.025622436705901]
AIC: 1247.6249547722084パラメータ推定には最適化用のパッケージであるOptim.jlを使用しています(GitHub).詳細な仕様はチェックしていませんが,勾配降下法やNelder-Mead法,ニュートン法などの一般的な最適化アルゴリズムはおおかた実装されているようです.ここではパラメータ範囲を制限したうえでL-BFGS法によりパラメータを最尤推定しています.ここでは
パラメータリカバリ
パラメータリカバリシミュレーションを行ってみましょう.ここでは適当な範囲の一様分布から生成した
N = 100
true_alpha = rand(100)
true_beta = rand(100) .* 3
est_alpha = Array{Float64}(undef, N)
est_beta = Array{Float64}(undef, N)
for i = 1:N
c, r = q_learning(true_alpha[i], true_beta[i])
f = params -> -log_likelihood(params, c, r)
result = optimize(
f,
[0.0, 0.0],
[1.0, 3.0],
[rand(), rand()],
Fminbox(LBFGS())
)
est_alpha[i] = Optim.minimizer(result)[1]
est_beta[i] = Optim.minimizer(result)[2]
end可視化してみる
可視化にはPlotsパッケージが使用可能です.ここでは散布図を描画したうえでSpearmanの順位相関係数を計算してみます.
using Plots
# パラメータリカバリの可視化
plot(scatter(
true_alpha,
est_alpha,
title = "Parameter Recovery",
xlabel = "True alpha",
xlims = (0, 1),
ylabel = "Estimated alpha",
ylims = (0, 1),
aspect_ratio = :equal
))
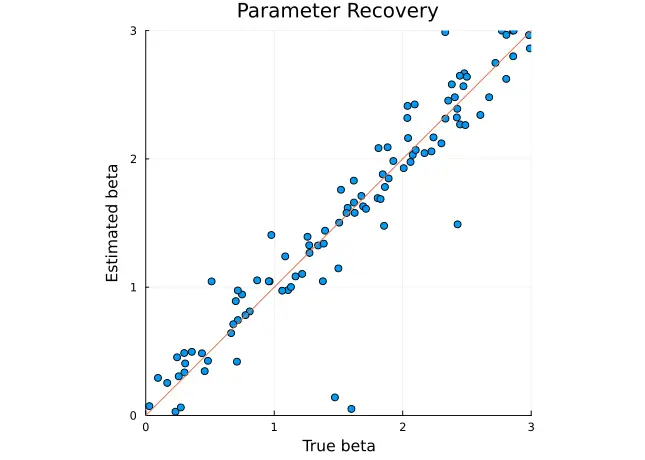
plot!(0:0.1:1, 0:0.1:1, legend = false)plot(scatter(
true_beta,
est_beta,
title = "Parameter Recovery",
xlabel = "True beta",
xlims = (0, 3),
ylabel = "Estimated beta",
ylims = (0, 3),
aspect_ratio = :equal
))
plot!(0:0.1:3, 0:0.1:3, legend = false)println("alpha: ", corspearman(true_alpha, est_alpha))
println("beta: ", corspearman(true_beta, est_beta))alpha: 0.8843410871359549
beta: 0.9474221113446927概ねちゃんとリカバリできているようでした.
まとめ
JuliaはRやPython,MATLABなどと文法的に似ている部分も多く,いろいろな言語のいいとこ取りをして直観的にコードを記述できる点が魅力だと思います.Jupyterとの統合もバッチリで,特にPythonを日常的に使用している人は簡単にワークフローに取り入れられるのではと思います.
とはいえ自分は生まれてこの方tidyverseの住人なので,習得できたとしても日常的に使うようになるかは微妙かもしれません.tidyverseの設計思想を踏襲したデータ分析用のパッケージとしてTidier.jlが開発中らしいのですが,RでもバックエンドでチューンされたC++が走っているので,日常のデータ分析で体感速度が大幅に向上するかどうかは微妙な気がします(ベンチマークテストではいちおう上回っているようですが).そのあたりはハンズオンで紹介があると思うので,手を動かして感触を確かめたいと思います.
今回のように単純なシミュレーションならRでも十分ですが,もっとrichなエージェントや複雑な環境を前提とすると計算の効率化のために細かい工夫が必要になってくると思います.計算資源も時間もない大学院生なので,そのあたりをJuliaで楽に解決できるようになると非常に嬉しいですね.機会があればもっと大規模なシミュレーションを実装してみたいと思います.
References
Wilson, R. C., & Collins, A. G. (2019). Ten simple rules for the computational modeling of behavioral data. Elife, 8.
片平健太郎. (2018). 行動データの計算論モデリング 強化学習モデルを例として. オーム社.